




So… is GPT-5 going to kill our startup?
Will it replace software development? Or, even weirder, will it replace the people for whom the software is made, eliminating the need for that software in the first place?
Those are the questions I was asking myself, in the depths of my AI angst.
Then, from a friend, who’s an investor:
So… how do I make sense of all these AI companies?
I didn’t have a good answer.
But as I started reading, I found some amazing essays. The only problem is that they’re all written for a technical audience. So this is my attempt to synthesize my learnings for a less-technical audience. Not only to synthesize, but to answer the questions from above, to put an end to the AI angst, and to come up with a framework that allows us to make informed decisions over the next, say, 18 months.
First Principles
People LOVE to talk about “thinking from first principles”. But here’s the thing — there’s no such thing as truly thinking from first principles. You have to make some assumptions. When you sit down to write an email, you don’t ask yourself, “Should I use a keyboard?” There’s not enough time in the day.
So when people say “thinking from first principles” what they really mean is: having a good instinct for knowing just how deep to dive into the stack of assumptions, from which point you rethink everything.
The most exciting thing about LLMs (to me, at least) is that they’re arising deeeeeeep in the stack of assumptions. Text. The computing interface from 1968. Humanistic thinking. Messy logic. A completely new way of telling a computer what to do.
LLMs will reorganize this stack of assumptions. And that makes it VERY difficult to think about LLMs from “first principles.”
So my goal is to dive into the stack of assumptions and find some solid ground. To figure out what GPT is and what it isn’t. And how it’s going to change over the next 18 months.
The Fundamentals, in 993 words
I know. Learning new things is terrible. It’s way more fun to just come up with uninformed, hot takes on Twitter. But I promise, if you can read the next 993 words, your takes will be so much hotter. I promise. So hot.
In case you were wondering — chatGPT is not the same thing as GPT-4.
chatGPT is a web app that is built on top of GPT-4. chatGPT has nice input box and a history of your chats.
GPT-4 is the model behind the scenes. You feed it text, it spits out text. That’s all it does.
In spite of the magical user experience 🧙♂️ and all the concern about existential risk 🦕 , there are 4 very real constraints on GPT-4.
It’s a machine that predicts the next word
Once the model is trained, the size of the input is capped
The “intelligence” is a function of compute, i.e. time and money
The final product is just a large file full of numbers
Note: These aren’t hard constraints. They’re not physical laws of the universe. But they will take time to overcome.
1. It’s a machine that predicts the next word
This is a random story, but somehow it’s a perfect analogy. Recently I got dinner with friends. Drinks were had. Afterwards, since this was a trendy place, they brought out a postcard with the check. Never seen that before. Anyway, we decided to write a postcard to another friend (not present). We passed the card around the table, and each person contributed one word before passing it again. We weren’t allowed to discuss our word choice with anyone else at the table.
This is exactly how GPT works. Not surprisingly our postcard was total gibberish. The amazing thing about GPT is that it produces “thoughts”, “answers”, “essays” — whatever you want to call it — by merely predicting the next word.
(Okay, so, technically, it doesn’t work with “words”, it works with vectors that represent meaning. I know, I know. What does “represent meaning” even mean? I’m not exactly sure. All I know is that some smart MFers figured out how to mathematically represent “donkey” such that a computer knows that it would be a foolish thing to say, “Pour me a cup o’ that donkey!” Anyway, the important thing to understand is that the model could conceivably work on any medium — e.g. video — as long as that medium can be converted into a series of vectors.)
Anyway, the image to keep in your mind is this little machine that predicts one more word. That gives us our first two constraints:
The model has no memory
When you’re “chatting” with the model, it feels like chatGPT understands the entire history of your chat, but that’s because the entire history is getting passed back to the model at every step. Each time the model “runs”, each time it “thinks”, it only produces one word.
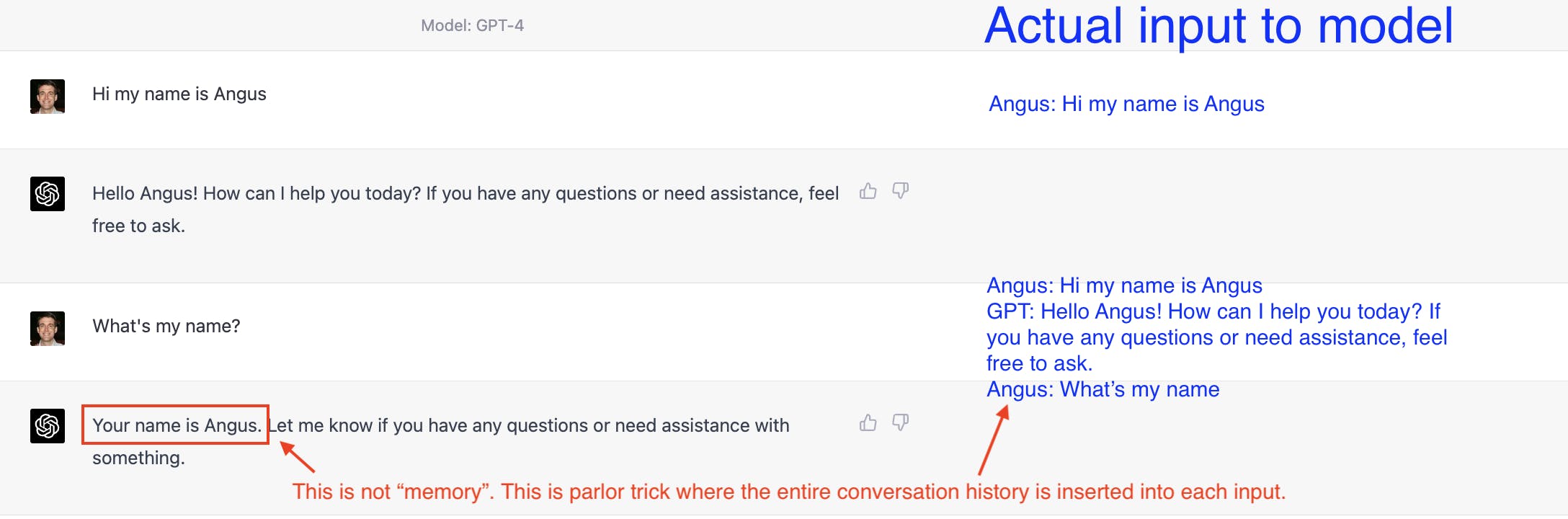
One word at a time → the speed is proportional to the length of the output
In the example above, it spits out:
Hello Hello Angus! Hello Angus! How Hello Angus! How can
Why does this matter? Well, I’m mostly interested in the ways that GPT will change software engineering. And yes, it writes essays much faster than you or I. But there are many places in a software system where you need code to execute instantaneously, and a 3-second response from GPT is a deal-breaker.
Like I said before, these are not hard constraints. The goal isn’t to predict what will happen in 20 years. It’s to understand where people’s time and energy will be spent over the next couple years. And a lot of effort will go into solutions and workarounds for these two constraints.
2. Once the model is trained, the size of the input is capped
If you’ve tried to completely replace your lawyer by pasting a long legal document into chatGPT, you will have have seen an error message that says, “The message you submitted was too long, please reload the conversation and submit something shorter.”
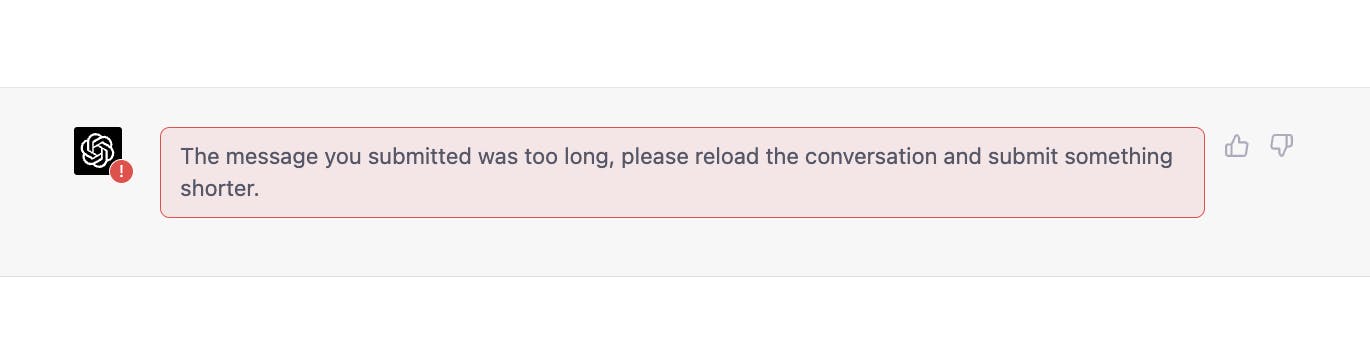
That’s because the input is capped.
(Another word for the input is the “context window”, which I’ll use from this point forward. I like “context window” because 1) “context” is a good reminder that the model’s output is a continuation of whatever came before it, and 2) “window” evokes a sense that the size is fixed.)
From OpenAI’s POV:
If OpenAI wants to make the context window bigger, they can. It’s simple. All they have to do is a train a bigger model. But that costs money. So, instead, they’re incentivized to make the smallest possible context window that keeps their users happy.
From an application developer’s POV:
The context window is a hugely important constraint. Let’s say that you’re building a product that does intelligent search across a codebase or a set of legal documents. The entire codebase will not fit into the context window. That means you need another model that can intelligently search for the information you want and fit it into the context window.
Over the next few years, there will be a massive amount of engineering effort and creativity that goes into this problem:
Search: How do you find the most relevant data to put into the context window?
System Design: How do you break up a problem into bite-size chunks, each of which are small enough to fit into the context window?
Compression: How do you compress data so that it fits into the context window?
3. The “intelligence” is a function of compute, i.e. time and money
OpenAI’s key insight was that the scale of the model is way more important than the technique used to build the model. So you need lots of money (or computers, or both) to compete in this space.
But that’s only useful for FANG CEOs. For the rest of us, the interesting constraint is time.
Quick aside on how the model is built:
OpenAI collects massive amounts of data
They “train” the model on the data over the period of many months. Basically they force it to look at some input, guess at the what output should be, and learn from that experience, like a zillion times.
At some point the model is deemed to be “trained”. Now it’s ready to “predict”, a.k.a. “infer”, a.k.a. “generate”, a.k.a. “chat”
Steps 1 and 2 take a really long time, like 6 months, maybe longer, I don’t know. This means that by the time they release GPT-X, it’s data is stale. GPT-4’s data only goes up to September 2021, for example.
This creates an interesting dynamic — let’s assume that GPT makes software engineers more productive than ever before. There will be more code written in the next 6 months than any 6-month window in human history, but…. GPT won’t have any knowledge of that code.
(Okay, so, another technical aside. They can “fine tune” the model, which means they quickly retrain it on more data. But fine-tuning is a hack. The results are much more brittle and less “intelligent” than the main model. So it’s more accurate to say that GPT is “dumbest” about things that have happened most recently.)
So this is another engineering challenge — how can we get the models to play catchup? How can we teach them new things without having to retrain the entire model at enormous cost?
4. The final product is just a large file full of numbers
This has two implications on distribution (and I’m speculating a bit here, because I don’t know exactly what the model output looks like, how they store it, how they encode it, etc.)
The file is relatively large (say, 5GB), which means it’s too large to fit directly onto a chip, too large to quickly load into memory on a cell phone, and too large to quickly download. Thus, the most logical mechanism for distribution is for 1) Sam Altman to run GPT on his Microsoft server and 2) for everyone else to access it over the internet.
The product seems like it’s… pretty easy to steal? It’s basically just one file. Maybe they have encryption and a customized way of running the model, but, if that’s the case, then it’s difficult to set up on your own. Point being, proprietary versions of GPT present an engineering challenge. They won’t be cheap.
Okay, To Recap
No memory
Small amounts of text in / text out
Can only be created by a government or massive corporation
Has a special set of skills
Autistic Savant Jason Bourne
GPT is a 35 year old polymath who was left for dead in the Mediterranean Sea, and when he gets pulled aboard an Italian fishing vessel he has NO MEMORY, but somehow he remembers how to [ugh, rubs forehead] DIAGNOSE A RARE NEURODEGENERATIVE DISORDER and [flashback] WRITE A PYTHON FUNCTION TO REVERSE A LINKED LIST and [mumbles in pain] COMPOSE A POEM ABOUT DONALD TRUMP IN THE STYLE OF LEWIS CARROLL.
You ask him ANY question and he stutters “G-g-g-g-g-g-” and then spits out a perfect response.
But then you ask him, “Wow, how’d you do that?” And he looks at you in bewilderment and asks “WHO ARE YOU?”
So, yea… He’s a little rough around the edges. But even so, he’s super useful! He’s better than Google + StackOverflow. He knows a shitload about AWS. He can write code. He can generate fake data. He’s an awesome sidekick.
But still, we’re talking about one autistic guy who answers questions really quickly. So what’s the big deal? How did we go from that to existential risk?
There are two reasons why he continues to sneak up on us: we’re really bad at reasoning about speed and scale.
When speed is so fast that quality doesn’t matter
Think about how hard it would have been to unravel the full implications of the microprocessor in the 60s. It was (and still is!) a machine that adds numbers together millions of times per second, and… that’s about it!
An accountant might have objected, “It can’t divide! It can’t work with decimals! It can’t think! It can’t review its work!” And they would have been right, but they were missing the big point — the microprocessor had just sped up addition by a factor of A MILLION, and, yes the “moves” available to a microprocessor were small (basically just simple arithmetic), but, at some point, a million little moves is better than one big fat thought.
The same is true today. GPT speeds up many forms of research by a factor of 1,000.
Let’s say you’re an investor, and you review 2,000 decks per year in 1,000 hours. Twitter idiots will say things like “Investing is dead 💀 GPT will review all decks 🤯 “. And then, in response to the idiots, investors, missing the point, will say, “It can’t handle .pptx as a file type, and it can’t make investment decisions, not even close”.
And they’d be right, but at some point, GPT will be able to review 2,000 decks in an hour. For like 7 cents. Literally. We’re talking about a 1000x speed up at 1/1,000,000th of the cost.
So yes, the software around GPT is still clunky. Yes, it makes mistakes. But it DOESN’T MATTER. Very little matters in the face of 1000x speed ups and 1000000x cost reductions. GPT will be worse than people in some ways, but we will simply reinvent processes around the strengths and weaknesses of this new tool.
Armies of Autistic Savant Jason Bournes
We’re bad with speed, and we’re equally bad with scale.
Here’s the thing: you don’t get one Autistic Savant Jason Bourne, you get as many as you want, at incredibly low cost.
Going back to the example of reviewing decks. What if each deck could be reviewed independently of all the others? Instead of having one Autistic Savant Jason Bourne chug through all 1,000 decks, you could recruit 1,000 Jason Bournes to work in parallel, and then dismiss them as soon as they’re done. Now, instead of taking an hour, the whole process could be done in 3 seconds.
Do you see where this is going? You could have GPT review every deck in the history of decks in a matter of seconds. Iterate. Ask the system a new question. It’d be a very powerful tool for a clever investor.
This technique is called “parallelization” and it’s the simplest way to scale GPT. But there are other possibilities. You can imagine having one Jason Bourne outsource work to another. One of them reviews decks, another one checks founder backgrounds, together they answer more complicated questions.
Precious gems versus grains of sand
To adopt the iPhone, you had to go buy a thing. To build apps on the iPhone, you had to learn a new programming language.
An iPhone is like a precious gem.
To adopt GPT, all you have to do is keep using the same software you already use. (Odds are you’ve already adopted it. It’s already baked into Salesforce, Notion, etc.) To build apps with GPT, you don’t have to learn anything. A software developer can get going in 10 minutes.
GPT is like grains of sand. They’re everywhere. They make their way into everything — in your shoes, stuck to your towel…
Shit, will there be anything left for humans to do?
In the next 18 months? Uh, yes. A lot.
chatGPT could not have written this essay, but I’ve used chatGPT about 100 times during the writing of this essay. I’ve searched for words, I’ve asked it clarifying questions about LLMs, I’ve condensed wordy paragraphs.
GPT 3
The process of writing a sentence might actually consist of 6 sub-tasks. In mid-2022, GPT was an interesting toy, but it wasn’t particularly helpful with any of these subtasks.
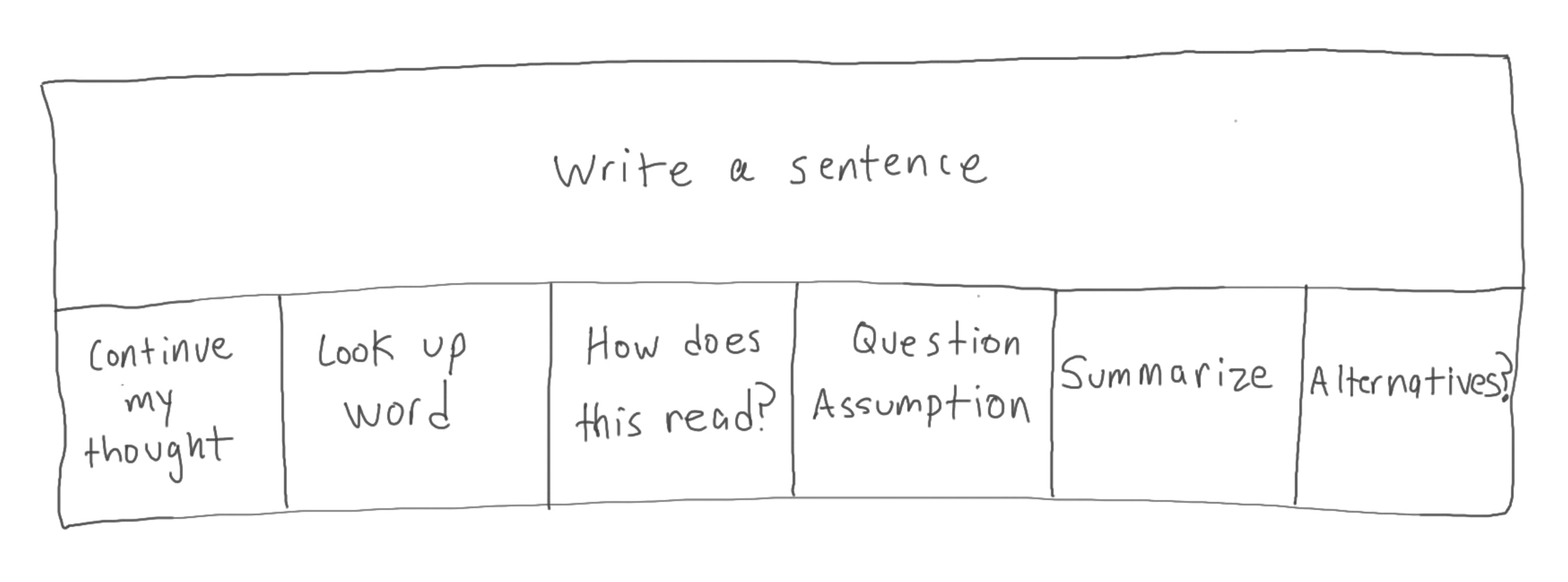
GPT 4
Fast forward to GPT-4. chatGPT is genuinely helpful with many of those subtasks. And this is great, because it frees up the mind to focus on the thought.
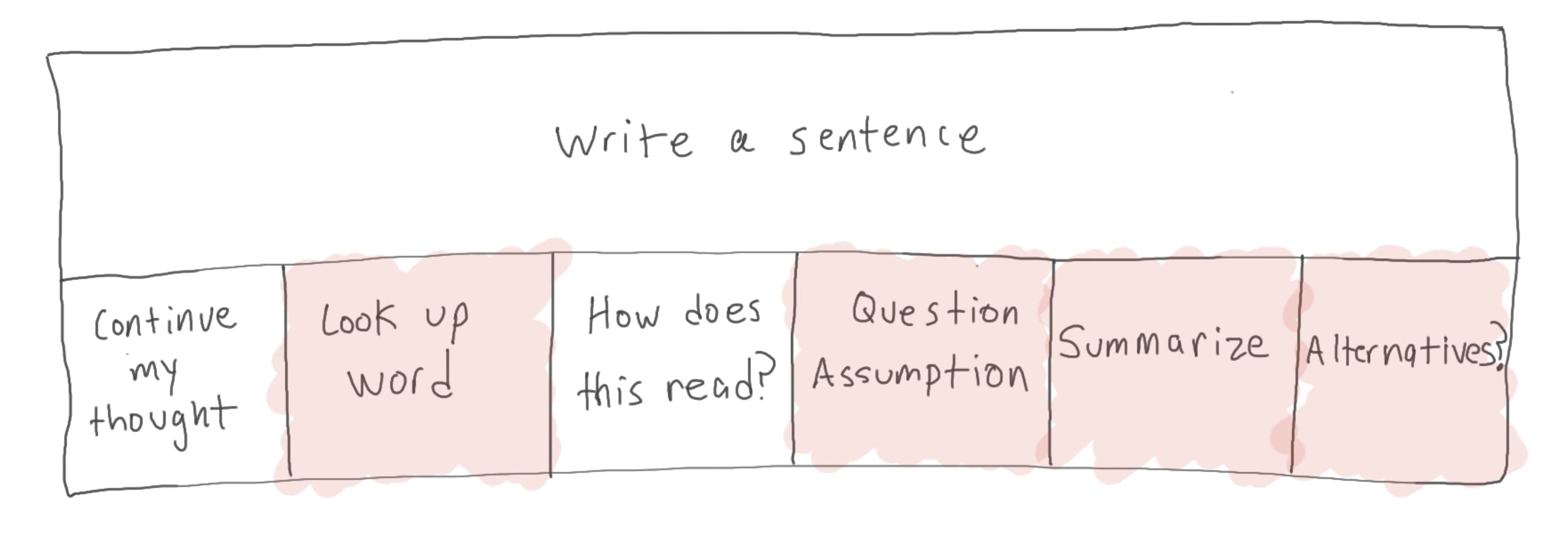
Looking forward
Now, what if chatGPT becomes good enough at ALL the subtasks that it swallows this entire process of writing a sentence?
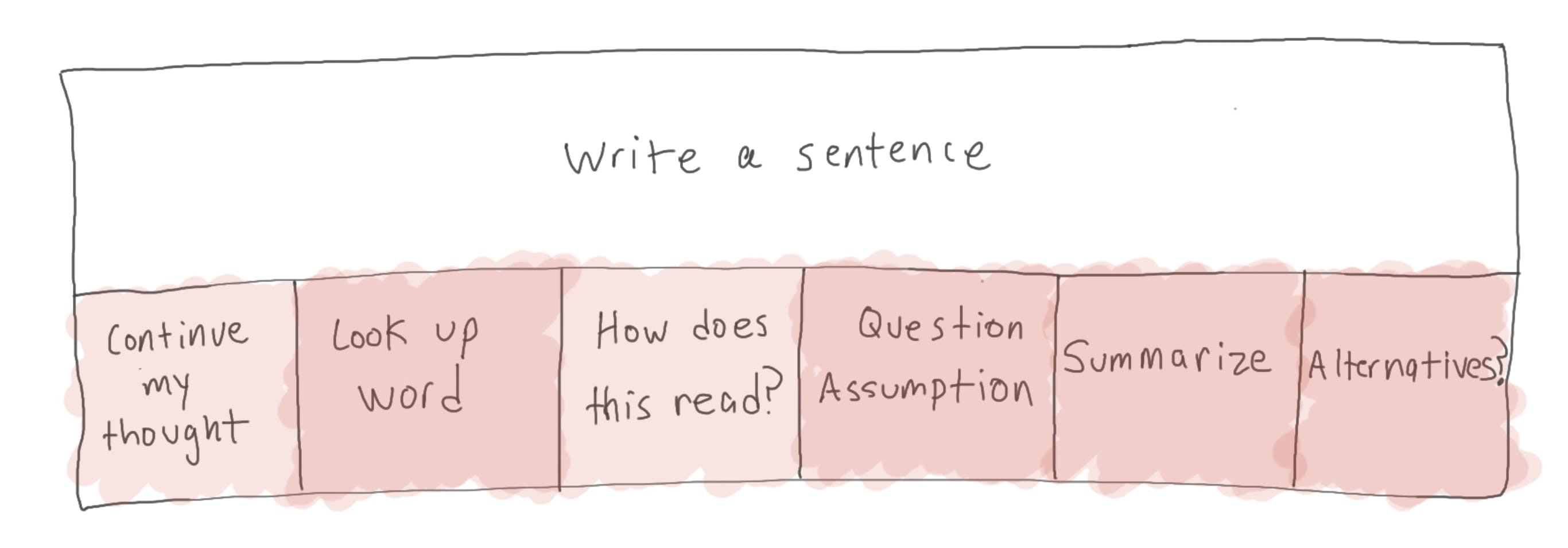
Zooming out, the human now delegates an entire task to GPT, focusing on “higher level” work.
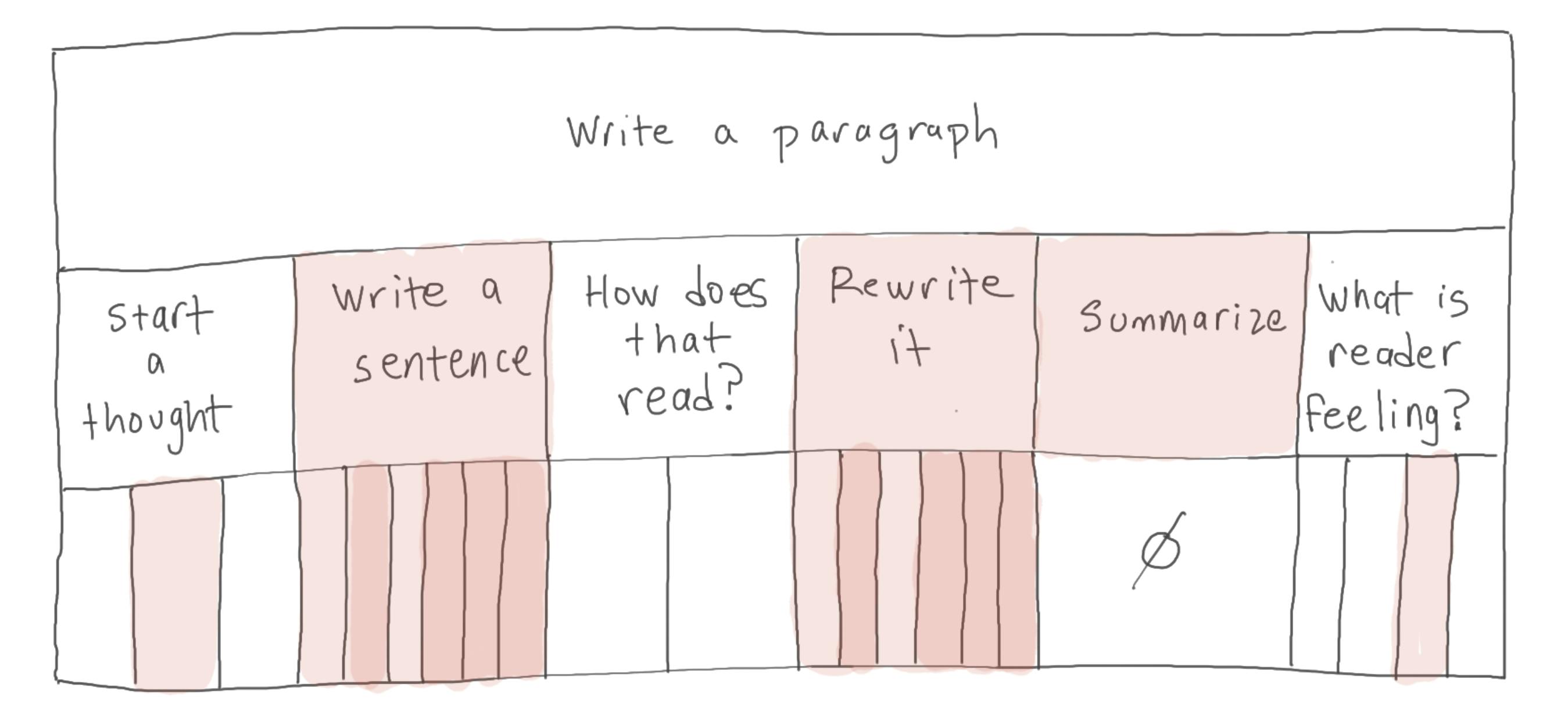
And so on… But can this go on forever? Once you start extrapolating, it’s easy to start drinking that AI Kool-aid. AI will take over everything! But I’ve got bad news for ya — it ain’t easy to automate a series of small tasks.
As a thought experiment, consider email.
Jason Bourne tackles email
If you had an army of Jason Bournes at your side, how would you delegate the task of email?
Seriously, close your eyes and imagine 10 amnesiac autistic savants in the room with you, right now.
Close your eyes…. there are 10 men in the room with you….
Does that feel… liberating? Helpful? Like it’s unlocking your creativity? Uh, probably not. Probably feels weird and stressful.
Let’s give it a shot though.
As a first cut, you could have one guy write emails for you. But you’d still have to go through every single email, so is that really that helpful?
Okay, what if you had one guy search for low priority emails and another guy write them? Now you’re starting to put menial work on autopilot, but you’d still want to review their work occasionally, you’d want to keep an eye on their costs, etc.
Next, what about responding to long running threads? Remember, they have a short attention span (that pesky context window). How do you compress the essence of a conversation down into something they can understand… 🤔
It turns out armies of Autistic Jason Bournes need a lot of help! Memory, coordination, tools for tinkering, monitoring, cost control…
Grab the popcorn
If this were a show about humanity, we’re at the scene where the CIA unveils Autistic Savant Jason Bourne in a lab.
Now we have to build armies of Jason Bournes to conquer drudgery. This is a massive project because these guys can’t remember shit! And we haven’t built ANY of the infrastructure for such an army.
What’s ahead for Jason Bourne, individual solider
Externalizing Jason Bourne’s thoughts, i.e. giving him some memory
Speeding up the rate at which he talks
Converting other media — code, pictures, video — into text (vectors, technically) that Jason can work with
Cramming our problems into the context window, either through search, problem division, or compression
Improving fine-tuning techniques so that we don’t have to train the whole thing over and over at massive cost
Creating variations of LLMs that fit onto chips, that can consume less memory, etc.
Creating proprietary LLMs so that, say, JPMorgan can run their own GPT in their own cloud
What’s ahead for the armies
Frameworks to help developers think in new ways
No-code tools for building LLM apps
Monitoring
Cost control
In Summary
So… is GPT-5 going to replace software development?
Not in the next 18 months. Beyond that, it seems that we will begin reinventing our processes around the strength of GPT, rather than GPT simply doing "human" tasks like a human.
Or, even weirder, will it replace the people for whom the software is made, eliminating the need for that software in the first place?
In retrospect, it’s a misleading question. LLMs will swallow more and more of the value chain, but people will work on increasingly higher-level tasks, which will require more software.
How do I make sense of all these AI companies?
If they solve any of the above problems, well… those are real problems. If they’re just slapping GPT onto an existing product, the barrier to using GPT Is basically zero, so they better have some other sort of moat.
Be strong!
In closing, I ask you to be strong!
This is an all-time Danger Zone for Bad Takes, for two reasons.
A lot of people with bad takes are way smarter than you. They’re machine learning PhDs who work at Google. What the hell do you know in comparison to them?
Speed and scale will break your brain (see above)
A Google employee recently leaked a document entitled "We have no moat, and neither does OpenAI." (The thesis is that both will lose to open source).
This is a historically Dangerous Bad Take because this person (they’re anonymous) is most definitely smarter than you. They’re an AI researcher at Google. They use Python libraries that you’ve never heard of. You, on the hand, use Excel, LIKE A GODDAMNED APE.
So what is this smart person missing? For one, they’re blatantly ignoring fundamental #3 — intelligence is a function of compute. Yes, open source models have made up ground on OpenAI, but that’s because they’re built on the backs of a leaked Facebook model and GPT-generated data.
Second, they’re treating a dynamic system like a static system. They’re treating OpenAI and open source like two separate worlds. The fact is, OpenAI is built on top of many open source innovations. You could argue that is their core competency! Taking open source ideas and applying capital and creativity to make a delightful final product.
Does OpenAI have business model risk? Yes (see Fundamental #4). Are they moat-less? No.
So be strong in the face of smart people with bad takes! Be strong!
Appendix: What to expect from GPT-5
GPT-5 is subject to the same constraints as GPT-4, so I expect them to pump more money into the model, and for the model to steadily improve. It’ll be smarter. It’ll have a bigger context window. It’ll run faster. (Altman has said that a “1M token” sized context window is possible. That would be 30x bigger than the context window today.)
Now the model is not the same thing as the product (remember, chatGPT ≠ GPT-4), and the product could be dramatically better.
For example:
They’ve demoed the ability to interpret images along with text. I expect to see that at some point, although Altman has said it won’t be a part of GPT-4, thanks to GPU shortages.
Instead of waiting for the free market, they could go ahead and solve some of the constraints themselves. For example, they could give the appearance of a dramatically larger context window by introducing a “compression” step behind the scenes.
Appendix: GPT in everything, or everything in GPT?
Almost every product now consists of a web app and an API. There’s ZenDesk, the web app, and then there’s the ZenDesk API, which allows programmers to integrate ZenDesk into third party products. And the same is true of GPT! There’s chatGPT, the web app, and there’s the GPT API.
So, will we use chatGPT with a ZenDesk Plugin (built using the ZenDesk API), or will we use ZenDesk with a GPT integration (built with the GPT API)?
One framework to think about this is the economics of UI. There’s a big upfront cost to building UI (these days, ”UI” is nearly synonymous with “website”). Right now, if you build a restaurant booking system, you have to build a website. Looking ahead, it’s not hard to imagine a world where the first version is simply an API that you put into users’ hands via a chatGPT Plugin.
On the other hand, the chatGPT interface can’t accommodate every use case in the world. At some point, the restaurant booking company will say to themselves, “We can grow our business by X% if we add features X, Y, and Z, and chatGPT doesn’t support those features, so we should invest in building a UI of our own.”
So in that world, simple chat experiences will live in chatGPT, but sophisticated chat experiences will live in 3rd party products, using the GPT API behind the scenes.
I will say, that framework ignores interactive effects. It’s possible that there are advantages to having a “one stop shop.” For example, you book your restaurant on chatGPT and then you immediately order your Uber as well. And while that may sound like a self-reinforcing feedback loop that’s impossible to stop, it’s important to remember that, at that point, it would be very easy for the restaurant booking system to add an Uber integration of their own.
The interactive effects are interesting to think about, but there is a reason that you can’t order a pizza on ZenDesk. There isn’t much overlap between resolving customer service tickets and eating pizza. There’s a reason that these products have boundaries.
Appendix: Inspirational Reading
OpenAI’s plans according to Sam Altman - Summary of interview with Altman
What is GPT doing… and why does it work? - Stephen Wolfram
Software 2.0 - Andrej Karpathy
Cheating is all you need - Steve Yegge (Jason Bourne was inspired by the Harvard CS grad analogy)
All the Hard Stuff Nobody Talks About when Building Products with LLMs - Phillip Carter
The rapture and the reckoning - Benn Stancil
Existential risk, AI, and the inevitable turn in human history - Tyler Cowen
I’ve really enjoyed Francois Chollet’s Twitter recently
Ditto for Roon
Thanks to Brian Timar, Ben Lynett, Alexey Guzey, Rob Churchill, Leeor Mushin, Will Schreiber, and Tyler Cowen for providing feedback